| Introduction | |||
|
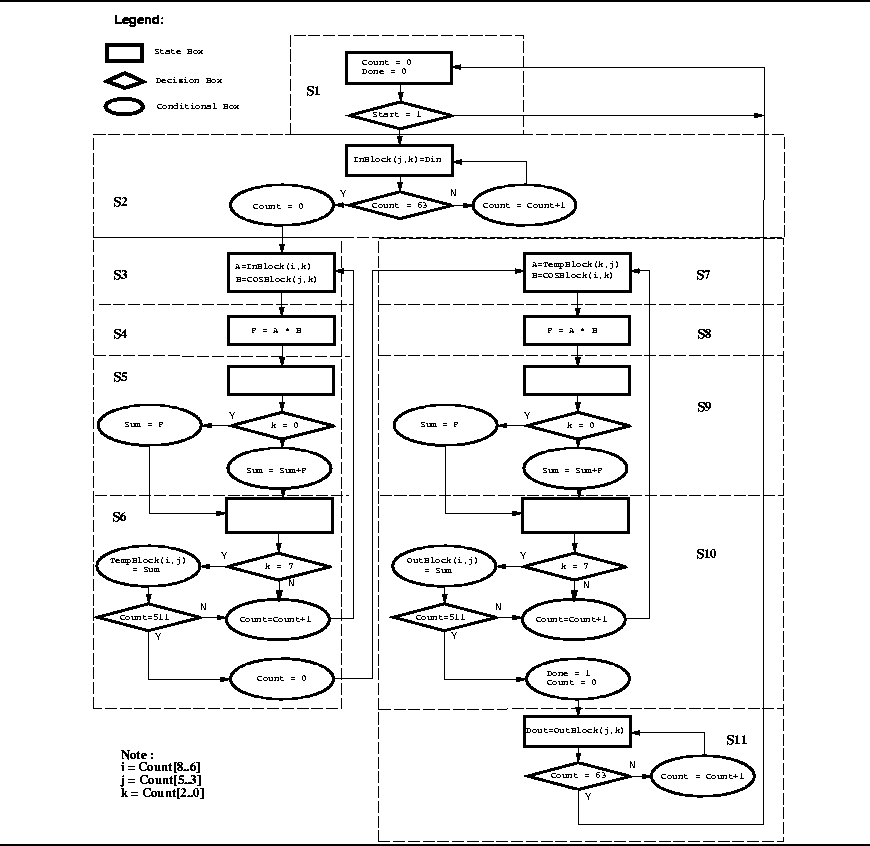
In this lab, you'll be developing a pipelined VHDL model for a pipelined ASM chart of the DCT chip and estimate the performance. In lab2, the performance of the most sequential version of our DCT chip is approximately 208,000 ns. In its ASM chart, we find that the performance obstacle is the loop iteration. Therefore, we have looked at these 3 optimization techniques to speed up the computation:
There is a shortcoming of these techniques: note that when we are doing P = A * B, the read-memory components are idle. When we are doing Sum = Sum + P, the multiplier is idle. The loop goes back to a new iteration only when it finishes the last state in the current loop. The loop pipelining technique increase the concurrency in the ASM chart: the next pair of matrix elements (A and B) to be multiplied does not necessarily need to enter the loop after the previous pair has finished. So while a set of data is being added to sum (Sum=Sum+P) the next set of data can be multiplied (P=A*B). We can potentially speed up our DCT computation based on this observation. However, care must be taken when you are designing a real pipelined model. In this lab, we are going to look at the techniques of VHDL pipeline modeling. the VHDL code for the sequential design is also provided below. You are responsible for improving performance of the present ASM chart, developing a new pipelined ASM chart and its VHDL model.
|
|||
| Sequential Design | |||
As shown, mapping from behavioral model to the most sequential design is pretty straight forward. Basically, we allocate 1 clock cycle for each set of operations that do not depend on each other. If you look at the source listing, you will see the VHDL process used to model the ASM chart. The behaviors associated with each block in ASM chart are grouped into a state. There is a variable ``State'' to keep track of where the current state is. The process is activated on every rising edge of the clock. Only those operations in the current state are excuted in the present clock cycle.
|
|||
| More Optimizations | |||
|
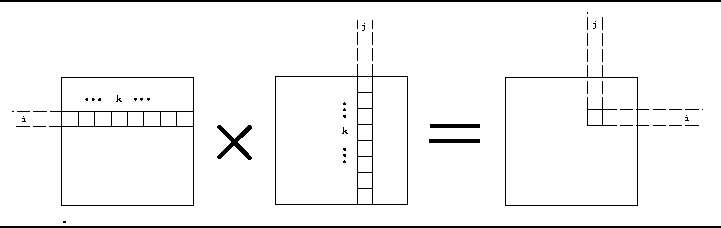
As we discussed in class, several optimization techniques can be applied to the sequential design in order to speed it up. For this lab, we will be doing Loop Pipelining. Note that loop pipelining can be combined with the optimizations done in previous lab like unrolling, chaining etc. to improve performance further. The pipeline for matrix multiplication example has 4 stages. These are:
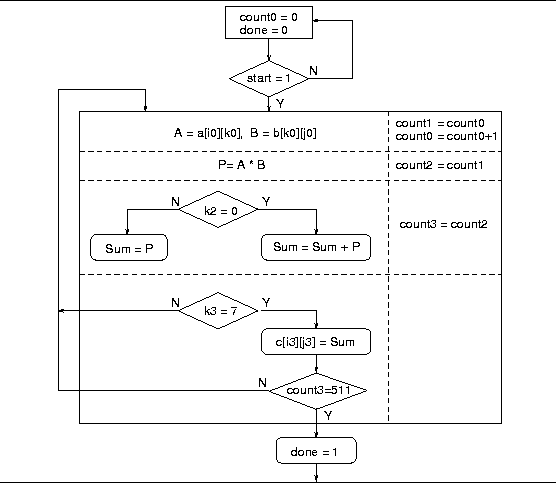
The ASM chart for the pipelined matrix multiplication alternative is shown in Figure 3. Note how the states for the non-pipelined case become stages for the pipelined model. The ASM chart given above, however, does not describe the complete pipelined design since it just shows that the stages and the computation done in each state when the pipeline if full. It does show the use of extra counters, viz., count1, count2 and count3. Since there are 4 sets of data in the pipeline, we need to keep track of the indices of these sets of data and hence need the registers. The pipeline timing diagram makes things more clear.
The timing diagram for the pipelined matrix multiplcation example is given in Figure 4. Note how the initial 3 states, S1, S2 and S3 fill up the pipeline, how all the 4 stages are active in State S4 and how the States S5, S6 and S7 flush the pipeline.
|
|||
| Assignment | |||
|
|||
| Source Listing | |||
Source listing for pipelined implementation of the Matrix Multiplication
example is given below. The
matrix.vhd
file multiplies two 8 × 8 matrices that have initialized
with some arbitrary integers.
The test bench compares the results of the matrix muplicator to the
correct results. Note how the states S1, S2, S3 fill up the
pipline and how the states S5, S6, S7 flush the pipeline. In state
S4 the pipeline is full and all stages are simultaneously active
(ofcourse, on different sets of data).
5.1 matrix.vhd5.2 clock.vhd5.3 tb.vhd |
|||